课程笔记:深度神经网络。
在非线性问题中,原始参数的数目增加往往会导致实际参数数目爆炸式增长(如果我们要拟合二次曲线,那么是$O(N^2)$,如果是三次,那么是$O(N^3)$),这会对线性回归或逻辑斯蒂回归很不利
0. 约定
- $a_i^{(l)}$: the ith activation value in layer l
- $\theta_{ba}^{(l)}$: the parameter of the edge between $a_a^{(l)}$ and $a_b^{(l+1)}$
- $a^{(l)}=g(z^{(l)})=g(\theta^{(l-1)}\cdot a^{(l-1)})$
1. Cost function
$J(\theta)$的求法和Logistic Regression基本相同,注意one-versus-all需要将K个Cost求和,同时因为存在多层参数,正则化也需要将所有的参数求和.
2. Activation Function
激活函数有很多种,除了sigmoid,ReLU,Tanh,这些激活函数都是非线性的。这是为了给线性的矩阵乘法引入非线性性,提升模型的表达能力。
- sigmoid将值映射到0-1区间,往往可以表达强度或者概率。
- ReLU简单,计算量少,有DropOut的功能。
- Tanh经过原点
- softmax一般用于多分类预测,并且配合CrossEntropy会更容易优化。
3. Back propagation
算法的关键在于求$\delta^{(l)}=\frac{\partial J(\theta)}{\partial z^{(l)}}$,我们可以形象地理解为其对最终结果的偏差所需要负的责任
- 依据$J(\theta)$,我们其实可以用微积分的知识很方便地推出$\delta^{(L)}=a^{(L)}-y$,下面都用一个训练样例来说明,因为训练样例的上标容易和层数的上标混淆
- 利用微分的链式法则,我们可以方便地求出每一层的
$$
\delta^{(l)}=\frac{\partial J(\theta)}{\partial z^{(L)}}…\frac{\partial z^{(l+1)}}{\partial z^{(l)}}=\delta^{(l+1)}\frac{\partial z^{(l+1)}}{\partial z^{(l)}}=(\theta^{(l)})^T\delta^{(l+1)}.*(1-a^{(l)})a^{(l)}
$$
- 求出梯度下降所需要的梯度
$$
\frac{\partial J(\theta)}{\partial \theta^{(l)}}=\frac{\partial J(\theta)}{\partial z^{(l+1)}} \frac{\partial z^{(l+1)}}{\partial \theta^{(l)}}=a^{l}(\delta^{l+1})^T
$$
4. Gradient checking
一个简单高效的检测back propagation是否有错的办法是在用微积分极限的思想求出梯度的近似值
$$
\frac{\partial J(\theta)}{\partial \theta_i}=\frac{J(…,\theta_i+\epsilon,…)-J(…,\theta_i-\epsilon,…)}{2*\epsilon}
$$
在如果多次反向传播中,近似的梯度和反向传播计算出的梯度非常近似,那么说明梯度下降没有问题。
5. Random initialization
如果用0初始化参数(例如np.zeros)可能会造成非常糟糕的结果。在数学上可以证明:初始$\theta=0$=>hidden layer的$\delta$和a层内是相同的,单个内部节点到下一层的所有参数都相等。最终的结果是hidden node实际上在计算相同的特征
6. Lab
注:Ng的训练集中0表示为10,在其给出的参考参数中,预测0也是最后一个预测器值最大。
6.1 Logistic regression
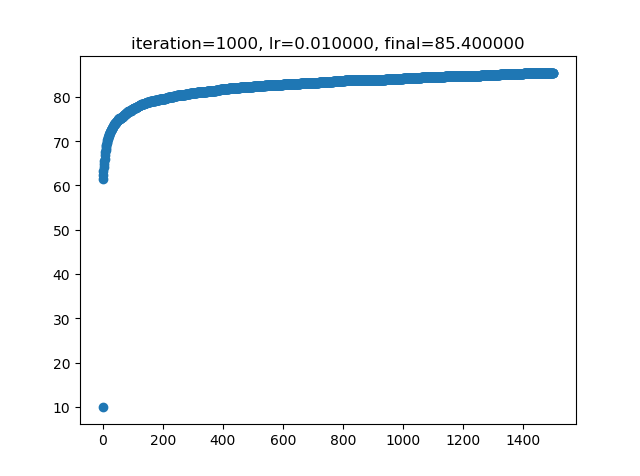
Cost function曲线。迭代1000次,学习率0.01,耗时数分钟。最后用训练之后的参数预测原有数据,准确率约为85.4%,尝试过更多次数的迭代,准确率没有明显提升。
6.2 Fully connected neural network
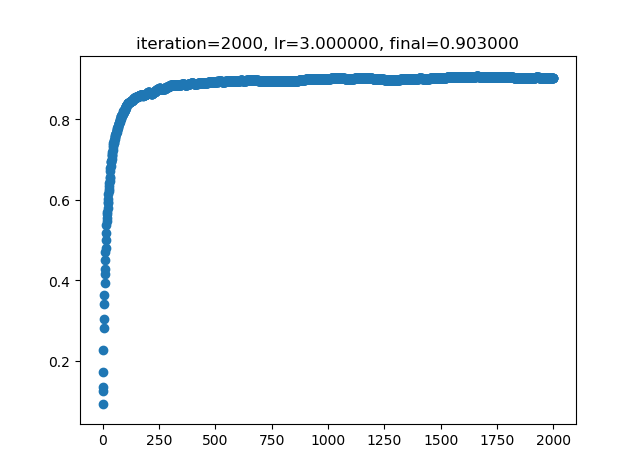
Accuracy曲线。迭代2000词,学习率3,耗时数分钟。训练数据大小4000,测试数据大小1000,无重合。测试准确率最后稳定在91%,尝试过更多次数的迭代,准确率没有明显提升。(如果测试数据和训练数据是同一个集合,那么准确率会偏高)
一件很尴尬的事:在学习率为0.01时nn学习速度很慢,我TM还以为是有bug调了好久。以后切记超参数先随便试试再debug。
6.3 Code
逻辑斯蒂的代码针对之前代码进行了少许修改,下面是最终版本
1 | import numpy as np |
下面是神经网络的代码
1 | import numpy as np |